
Building & Training a Transformer Model from Scratch

Motivation
Recently, I built my first Transformer model from scratch and then trained it on a simple German to English translation task.
Why did I do this? I want to build a small general purpose language model from scratch, one like a model from the Llama series, etc. And, I believe this is my first step towards understanding how I can do that.
In this article, I walkthrough the code I put together to build & train this transformer model. My implementation of the Transformer model closely follows the model described in Attention Is All You Need paper.
Furthermore, to understand the code I present in this article, all you’ll need is a decent understanding of the Pytorch library.
Finally, I want to express my immense gratitude to anyone giving this article a read. I would love to hear your thoughts, suggestions, areas of improvement, etc. Feel free to reach out to me on LinkedIn. Let’s talk!
End-to-End Implementation
I’ve put together this notebook that runs the code in this article from start to finish. I suggest using Google Colab Pro (preferably Colab Enterprise) to execute it.
Annotated Code
This section is going to be a code-reading exercise with detailed comments explaining every non-trivial line of code. I truly believe code-reading is the most effective way of understanding implementations.
Building a Transformer Model
The following parts will illustrate the building blocks of a Transformer model, culminating with a model assembly.
Multi-Head Attention
class MultiAttention(nn.Module):
"""Scaled dot-product Multi-Head Attention.
Args:
k (int): Number of embedding dimentions.
heads (int): Number of heads.
"""
def __init__(self, k, heads=4):
"""Initialize the linear layers to convert input
into queries, keys and values. We also initialize
the linear layer which projects the output of
the multi-head attention mechanism.
"""
super().__init__()
assert k%heads == 0
self.k, self.heads = k, heads
self.tokeys = nn.Linear(k, k, bias=False)
self.toqueries = nn.Linear(k, k, bias=False)
self.tovalues = nn.Linear(k, k, bias=False)
self.finalprojection = nn.Linear(k, k)
def forward(self, xq, xk, xv, mask=None):
"""Compute multi-head attention.
Args:
xq (Tensor): Input to the linear layer (self.toqueries)
that produces the query matrix.
xk (Tensor): Input to the linear layer (self.tokeys)
that produces the key matrix.
xv (Tensor): Input to the linear layer (self.tovalues)
that produces the value matrix.
mask (Tensor): Shape: (t, t), a bool tensor. True values
determine the location of elements to be masked.
t -> sequence length
"""
# b -> batch size
# s -> basically the thickness of each attention head
b, _, k = xq.size()
h = self.heads
s = k // h
# We transform the input (xq, xk, xv) into queries, keys & values,
# and reshape these quries, keys & values into matrices of
# (batch_size, sequence_len, heads, head_thickness) dimention
queries = self.toqueries(xq).view(b, -1, h, s)
keys = self.tokeys(xk).view(b, -1, h, s)
values = self.tovalues(xv).view(b, -1, h, s)
queries = queries.transpose(1, 2).contiguous().view(b*h, -1, s)
keys = keys.transpose(1, 2).contiguous().view(b*h, -1, s)
values = values.transpose(1, 2).contiguous().view(b*h, -1, s)
# This is the first operation in the attention mechanism, where we
# multiply the query and key matrices using bmm. Next, we multiply
# the output of bmm with a scaling factor.
# torch.bmm is used for batched matrix multiplication
QK = torch.bmm(queries, keys.transpose(1, 2))
QK = QK/(s**0.5) # Shape: (batch_size * num_heads, seq_len, seq_len)
# Next, we mask the output of the previous opration.
# This masking is done to prevent attention being calculated on,
# 1. padding_tokens in the input & output
# 2. tokens after position 'i' while training or predicting on
# position 'i' in output.
if mask is not None:
expanded_mask = mask.repeat_interleave(self.heads, dim=0)
QK.masked_fill_(expanded_mask, -1e9)
# We now perform the softmax operation. We can think of this
# to be the fraction of attention each token has on all
# other tokens.
# QK Shape: (batch_size * num_heads, seq_len, seq_len)
QK = F.softmax(QK, dim=2)
# Almost there, next we perform a bmm between the output
# of softmax layer and the value matrix.
out = torch.bmm(QK, values).view(b, h, -1, s)
out = out.transpose(1, 2).contiguous().view(b, -1, h*s)
# Finally, we project the output of the previous
# operation using a dense layer.
return self.finalprojection(out)Encoder & Decoder
Our Transformer is made of N Encoder blocks and N Decoder blocks. In the next two parts let's define both of these blocks.
Encoder
class EncoderBlock(nn.Module):
"""An Encoder Block.
Args:
k (int): Number of embedding dimentions.
heads (int): Number of heads.
"""
def __init__(self, k, heads, dropout_rate):
"""Initialize the multi-head attention, layer normalization,
dropout and dense layers. These form the meat of a
Encoder block.
"""
super().__init__()
self.mhs_attention = MultiAttention(k, heads)
self.norm1 = nn.LayerNorm(k)
self.norm2 = nn.LayerNorm(k)
self.dropout1 = nn.Dropout(p=dropout_rate)
self.dropout2 = nn.Dropout(p=dropout_rate)
# The hidden layer doesn't need to be 4 times larger, it
# just needs to be larger than the encoding dimentation k.
self.ff = nn.Sequential(
nn.Linear(k, 4*k),
nn.ReLU(),
nn.Linear(4*k, k)
)
def forward(self, x, x_mask):
"""Perform a forward pass through the Encoder block.
Args:
x (Tensor): Output of the previous Encoder block. For the
first Encoder block, x is the prompt given to the
Transformer (language model).
x_mask (Tensor): Shape: (t, t), a bool tensor.
True values determine the location of elements to be masked.
t -> sequence length
"""
# Forward pass through the multi-head attention layer.
attention_out = self.mhs_attention(xq=x, xk=x, xv=x, mask=x_mask)
# Implement dropout, establish a residual connection and
# perform a forward pass through the Layer Normalization layer.
x = self.norm1(self.dropout1(attention_out) + x)
# Forward pass through the dense layer.
ff_out = self.ff(x)
# Implement dropout, establish a residual connection from the
# output of previous normalization layer, and perform a
# forward pass through the next Layer Normalization layer.
# output dimentation (b, t, k)
return self.norm2(self.dropout2(ff_out) + x)Decoder
class DecoderBlock(nn.Module):
"""A Decoder block.
Args:
k (int): Number of embedding dimentions.
heads (int): Number of heads.
"""
def __init__(self, k, heads, dropout_rate):
"""Initialize multi-head attention, layer normalization
dropout and dense layers. These form the meat of a Decoder block.
"""
super().__init__()
self.mhs_attention1 = MultiAttention(k, heads)
self.mhs_attention2 = MultiAttention(k, heads)
self.norm1 = nn.LayerNorm(k)
self.norm2 = nn.LayerNorm(k)
self.norm3 = nn.LayerNorm(k)
self.dropout1 = nn.Dropout(p=dropout_rate)
self.dropout2 = nn.Dropout(p=dropout_rate)
self.dropout3 = nn.Dropout(p=dropout_rate)
self.ff = nn.Sequential(
nn.Linear(k, 4*k),
nn.ReLU(),
nn.Linear(4*k, k)
)
def forward(self, x, y, x_mask, y_mask):
"""Perform a forward pass through the Decoder block.
Args:
x (Tensor): The output from a stack of N Encoder blocks.
y (Tensor): Output of the previous Decoder block. For the
first Encoder block, y is the target corresponding
to the prompt.
x_mask (Tensor): Shape: (xt, xt), a bool tensor and a mask
for x. True values determine the location of elements
to be masked.
xt -> sequence length of x
y_mask (Tensor): Shape: (yt, yt), a bool tensor and a mask
for y. True values determine the location of elements
to be masked.
yt -> sequence length of y
"""
# Forward pass through the first multi-head attention layer.
attention1_out = self.mhs_attention1(xq=y, xk=y, xv=y, mask=y_mask)
# Implement dropout, establish a residual connection and
# perform a forward pass through the Layer Normalization layer.
y = self.norm1(self.dropout1(attention1_out) + y)
# Check the values passed for xq, xk, and xv.
# y -> output from the previous operation
# Forward pass through the second multi-head attention layer.
attention2_out = self.mhs_attention2(xq=y, xk=x, xv=x, mask=x_mask)
# Implement dropout, establish another residual connection and
# perform a forward pass through the
# second Layer Normalization layer.
x = self.norm2(self.dropout2(attention2_out) + y)
# Forward pass through the dense layer.
ff_out = self.ff(x)
# Implement dropout, establish the final residual connection from
# the output of the previous normalization layer, and perform
# a forward pass through the final Layer Normalization layer.
# output dimentation (b, t, k)
return self.norm3(self.dropout3(ff_out) + x)Transformer
Now, let's put everything together to build our Transformer model.
class Transformer(nn.Module):
"""The Transformer model.
Args:
k (int): Number of embedding dimentions.
heads (int): Number of heads.
x_seq_length (int): Maximum length of the input sequence.
y_seq_length (int): Maximum length of the output sequence.
x_vocab (int): Size of the source vocabulary.
y_vocab (int): Size of the target vocabulary.
n_encoders (int): Number of Encoder blocks in the Transformer model.
n_decoders (int): Number of Decoder blocks in the Transformer model.
"""
def __init__(
self,
k,
heads,
x_seq_length,
y_seq_length,
x_vocab,
y_vocab,
n_encoders=2,
n_decoders=2,
dropout_rate=0.1
):
"""Initialize the embedding lookup tables, the Encoder & Decoder
stack and the final linear layer.
"""
super().__init__()
self.k = k
self.x_token_emb = nn.Embedding(x_vocab, k)
self.x_pos_emb = nn.Embedding(x_seq_length, k)
self.y_token_emb = nn.Embedding(y_vocab, k)
self.y_pos_emb = nn.Embedding(y_seq_length, k)
self.dropout1 = nn.Dropout(p=dropout_rate)
self.dropout2 = nn.Dropout(p=dropout_rate)
self.eblocks = []
for i in range(n_encoders):
self.eblocks.append(
EncoderBlock(k=k, heads=heads, dropout_rate=dropout_rate)
)
self.eblocks = nn.ModuleList(self.eblocks)
self.dblocks = []
for i in range(n_decoders):
self.dblocks.append(
DecoderBlock(k=k, heads=heads, dropout_rate=dropout_rate)
)
self.dblocks = nn.ModuleList(self.dblocks)
self.linear = nn.Linear(k, y_vocab)
def forward(self, x, y, x_mask, y_mask):
"""Perform a forward pass through the Transformer model.
Args:
x (Tensor): The prompt given to the Transformer (language model)
y (Tensor): The target corresponding to the prompt.
x_mask (Tensor): Shape: (xt, xt), a bool tensor and a mask
for x. True values determine the location of elements
to be masked.
xt -> sequence length of x
y_mask (Tensor): Shape: (yt, yt), a bool tensor and a mask
for y. True values determine the location of elements
to be masked.
yt -> sequence length of y
"""
# Produce token embeddings for x & y.
x_tokens = self.x_token_emb(x)
y_tokens = self.y_token_emb(y)
b, t_x, k = x_tokens.size()
_, t_y, _ = y_tokens.size()
# Produce positional embeddings for x. Provides the
# Transformer model with the information on position of
# each token in x.
x_positions = torch.arange(t_x, device=device)
x_positions = self.x_pos_emb(x_positions)[None, :, :].expand(b, -1, k)
# Produce positional embeddings for y. Provides the
# Transformer model with the information on position of
# each token in y.
y_positions = torch.arange(t_y, device=device)
y_positions = self.y_pos_emb(y_positions)[None, :, :].expand(b, -1, k)
# Combine the token embeddings & positional embeddings
# to form a single rich vector and then implment dropout to
# define each input (x) & output (y).
x = self.dropout1(x_tokens + x_positions)
y = self.dropout2(y_tokens + y_positions)
# Forward pass through each of the Encoder blocks.
for eblock in self.eblocks:
x = eblock(x, x_mask)
# Forward pass through each of the Decoder blocks.
for dblock in self.dblocks:
y = dblock(x, y, x_mask, y_mask)
# Forward pass through the final linear layer.
# Output shape: (batch_size, y_seq_length, y_vocab)
y = self.linear(y)
# Produce the probability of next token.
# log of softmax is important since we plan to use
# the KL Divergence loss.
# Output shape: (batch_size, y_seq_length, y_vocab)
return F.log_softmax(y, dim=2)
def encode(self, x, x_mask):
"""Forward pass through the stack of Encoders.
"""
x_tokens = self.x_token_emb(x)
b, t, k = x_tokens.size()
positions = torch.arange(t, device=device)
positions = self.x_pos_emb(positions)[None, :, :].expand(b, -1, k)
x = self.dropout1(x_tokens + positions)
for eblock in self.eblocks:
x = eblock(x, x_mask)
return x
def decode(self, encoder_out, y, x_mask, y_mask):
"""Forward pass through the stack of Encoders.
"""
y_tokens = self.y_token_emb(y)
b, t, k = y_tokens.size()
positions = torch.arange(t, device=device)
positions = self.y_pos_emb(positions)[None, :, :].expand(b, -1, k)
y = self.dropout2(y_tokens + positions)
for dblock in self.dblocks:
y = dblock(encoder_out, y, x_mask, y_mask)
decoded_out = self.linear(y)
return F.log_softmax(decoded_out, dim=2)Dataset Prepration
Next, load the tokenizers, prepare the dataset, and build the vocabularies.
Load Tokenizers
# Load spacy's english and german tokenizers.
spacy_de = spacy.load("de_core_news_sm")
spacy_en = spacy.load("en_core_web_sm")Load the Dataset
def rename_keys(row):
"""This function is designed to be used with
the `datasets.Dataset.map()` method. It modifies the
'translation' column in-place by renaming the nested keys
from 'en' to 'input' and from 'de' to 'output'.
Args:
row (dict): A dictionary representing a
single row from a Hugging Face Dataset.
It is expected to have a nested 'translation' dictionary
with 'en' and 'de' keys.
Returns:
dict: The modified row dictionary with the renamed
keys in the 'translation' field.
"""
row["translation"]["input"] = row["translation"].pop("de")
row["translation"]["output"] = row["translation"].pop("en")
return row
# Load the train, validation & test split of
# 1M examples from the WMT 2014 German to English translation dataset.
data = load_dataset("wmt/wmt14", "de-en")
train = data["train"][:1_000_000]["translation"]
validation = data["validation"]["translation"]
test = data["test"]["translation"]Build the Vocabularies
Now, let’s define a Vocabulary class with useful methods to easily navigate between string tokens and integer token IDs.
class Vocabulary():
"""Lightweight vocabulary that maps between string tokens
and integer token IDs.
Args:
los (List[String]): List of strings from which
to build a vocabulary.
"""
def __init__(self, los):
"""Initialize the vocabulary and the lookup hashmaps.
"""
self.vocab = los
# Build the string to integer ID mapping.
self.stoi = {}
for i, s in enumerate(self.vocab):
self.stoi[s] = i
# Build the integer ID to string mapping.
self.itos = {}
for i, s in enumerate(self.vocab):
self.itos[i] = s
def __len__(self):
"""Returns the size of the vocabulary.
"""
return len(self.vocab)
def __getitem__(self, i):
"""Retuns the string token when provided with
the integer token ID.
"""
return self.vocab[i]
def __call__(self, string_tokens_lis):
"""Convert an iterable of string tokens to their
corresponding integer IDs.
Args:
string_tokens_lis (Iterable[str]): Sequence of token
strings to convert.
Returns:
list[int]: Integer token IDs for the provided string
tokens.
"""
return [self.stoi[s] for s in string_tokens_lis]
def get_stoi(self):
"""Returns the string-to-index (STOI) mapping.
"""
return self.stoi
def get_itos(self):
"""Returns the index-to-string (ITOS) mapping.
"""
return self.itosNext up, we’ll define some useful functions that will help us build our input (x) and output (y) vocabularies.
def tokenize(text, tokenizer):
"""Returns a list of tokenized strings.
Example:
>>> tokenize("Hello, world!", tokenizer)
['Hello', ',', 'world', '!']
"""
return [tok.text for tok in tokenizer.tokenizer(text)]def load_vocab(
input_tok,
output_tok,
train,
validation,
test,
bypass=False
):
"""Builds input (x) and output (y) vocabulary and returns them as a
Vocabulary object.
Args:
train (Iterable[Mapping[str, str]]) Training examples.
validation (Iterable[Mapping[str, str]]) validation examples.
test (Iterable[Mapping[str, str]]) test examples.
input_tok: Input tokenizer (spaCy-like).
output_tok: Output tokenizer (spaCy-like).
bypass (bool): If True always builds the vocabulary.
Returns:
(Vocabulary): Input vocabulary.
(Vocabulary): Output vocabulary.
(int): Maximum length of a sequence in input.
(output): Maximum length of a sequence in input.
"""
if not os.path.exists("vocab.pt") or bypass:
x_vocab, x_max_seq_len = return_lis_unique_tokens(
train, validation, test, input_tok, "input"
)
y_vocab, y_max_seq_len = return_lis_unique_tokens(
train, validation, test, output_tok, "output"
)
torch.save(
(x_vocab, y_vocab, x_max_seq_len, y_max_seq_len), "vocab.pt"
)
else:
x_vocab, y_vocab, x_max_seq_len, y_max_seq_len = torch.load("vocab.pt")
return Vocabulary(x_vocab), Vocabulary(y_vocab), x_max_seq_len, y_max_seq_lenWe can define our input (x) and output (y) vocabularies now.
# Build the input (x) and output (y) vocabulary.
x_vocab, y_vocab, x_max_seq_len, y_max_seq_len = load_vocab(
spacy_de, spacy_en, train, validation, test, bypass=True
)Finally, Training the Transformer model…
First, let's define a class to track some information while model training.
class TrainState:
"""Tracks the number of steps, examples, and tokens processed"""
# Steps in the current epoch
step: int = 0
# Number of gradient accumulation steps
accum_step: int = 0
# total # of examples used
samples: int = 0
# total # of tokens processed
tokens: int = 0Learning Rate & Loss Function
This is arguable the most important section of all. In this section we will define,
A function that returns the learning rate at every training step,
A class that we will use for loss calculation and
A simple wrapper around the loss calculation class.
def rate(step, k, factor, warmup):
"""Returns the learning rate at every step.
Varying the learning rate is one of the central requirement
in a Transformer model. This learning rate
formula is sourced from the Attention Is All You
Need paper.
Args:
step (int): Current step in the training process.
k (int): Number of embedding dimentions.
factor (float): Multiplicative factor applied to the learning
rate at each step; values < 1.0 decay it, > 1.0 increase it.
warmup (int): The step until which we increase the learning rate.
Number of initial training steps during which the learning rate
ramps up; after these steps, the main schedule applies.
Note:
- We have to default the step to 1 for LambdaLR function
to avoid zero raising to negative power.
"""
if step == 0:
step = 1
return factor * (
k ** (-0.5) * min(step ** (-0.5), step * warmup ** (-1.5))
)class LabelSmoothing(nn.Module):
"""Implement label smoothing.
Note:
In Label smoothing, instead of assigning a probability of 1.0 to the
correct class and 0.0 to all others, it gives a high probability
to the correct class (`confidence`) and a small, uniform probability
(`smoothing / (size - 2)`) to the incorrect classes. The padding
index is always assigned a probability of 0.0. This regularization
technique prevents the model from becoming overconfident in its
predictions and can improve generalization.
"""
def __init__(self, size, padding_idx, smoothing=0.0):
"""Initialize the loss function and other useful data points.
"""
super(LabelSmoothing, self).__init__()
# Initializing the loss function.
self.criterion = nn.KLDivLoss(reduction="sum")
self.padding_idx = padding_idx
self.confidence = 1.0 - smoothing
self.smoothing = smoothing
self.size = size
self.true_dist = None
def forward(self, x, target):
"""Calculates the loss. Also, applied label smoothing to the
target (next token probability) tensor.
Args:
x (torch.Tensor): The model's output logits.
target (torch.Tensor): The ground-truth target labels.
Returns:
(torch.Tensor): The computed Kullback-Leibler (KL) divergence loss
between the model's output and the smoothed target
distribution.
"""
assert x.size(1) == self.size
true_dist = x.data.clone()
# Build the smooth target distribution.
true_dist.fill_(self.smoothing / (self.size - 2))
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)
# Assign padding tokens positions a value of 0.0
true_dist[:, self.padding_idx] = 0
mask = torch.nonzero(target.data == self.padding_idx)
if mask.dim() > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist = true_dist
# Calculate KL Divergence loss.
return self.criterion(x, true_dist.clone().detach())class SimpleLossCompute:
"""A wrapper to compute loss.
Args:
criterion: An instance of LabelSmoothing class.
"""
def __init__(self, criterion):
"""Initialize SimpleLossCompute.
"""
self.criterion = criterion
def __call__(self, x, y, norm):
"""Compute the loss.
Args:
x (Tensor): model output
y (Tensor): target
Returns:
(Tensor): Normalized loss.
(Tensor): Un-normalized loss.
"""
sloss = (
self.criterion(
x.contiguous().view(-1, x.size(-1)), y.contiguous().view(-1)
)
/ norm
)
return sloss.data * norm, slossBatch Prepration
In the following section, we will define a Batch class to house information on each batch of data. In this class we’ll prepare & maintain masks for the input (x) and target (y) tensors, another extremely important step in training our Transformer model.
class Batch:
"""For holding a batch of data with mask during training."""
def __init__(self, x, tgt=None, pad=2):
"""Initialize batch object.
Args:
x (Tensor): Input to the stack of Encoders.
tgt (Tensor): Expected model (decoder) output aka target.
pad (int): Padding token integer ID.
"""
self.x = x
# Build the input mask to hide padding tokens.
self.x_mask = (x == pad).unsqueeze(-2)
if tgt is not None:
# decoder input
self.tgt = tgt[:, :-1]
# for loss calculation
self.tgt_y = tgt[:, 1:]
# Build the output mask to hide padding tokens
# and future words.
self.tgt_mask = self.make_std_mask(self.tgt, pad)
self.ntokens = (self.tgt_y != pad).data.sum()
@staticmethod
def make_std_mask(tgt, pad):
"""Build a target mask to hide padding and future words.
Args:
tgt (Tensor): Expected model (decoder) output aka target.
pad (int): Padding token integer ID.
"""
# Create a bool tensor of tgt.shape shape with True values
# in location of padding token integer ID.
tgt_mask = (tgt == pad).unsqueeze(-2)
# Add True values (in upper triangualr matrix fashion,
# without diagnoal) for future words in the tgt_mask.
tgt_mask = tgt_mask | (torch.triu(
torch.ones((1, tgt.size(1), tgt.size(1))), diagonal=1
)==1).type_as(tgt_mask.data)
return tgt_maskTrain & Validation Data Loaders
First, we’ll build a simple class to build a map-style dataset.
class MapDataset(Dataset):
"""A simple map-style dataset that wraps a list of data.
This class implements the `__len__` and `__getitem__` methods, making it
compatible with PyTorch's `DataLoader`. It's a basic way to create a
dataset from an existing list in memory.
Args:
data_list (List[str]): A list of data points, where each element
represents a single sample.
"""
def __init__(self, data_list):
"""Initialize MapDataset.
"""
self.data_list = data_list
def __len__(self):
"""Returns the total number of samples in the dataset.
"""
return len(self.data_list)
def __getitem__(self, idx):
"""Retrieves the sample at the specified index.
Args:
idx (int): The index of the sample to retrieve.
Returns:
Any: The data sample at the given index.
"""
return self.data_list[idx]The next step is to create a couple of functions that build train & validation data loaders.
def collate_batch(
batch,
x_pipeline,
y_pipeline,
x_vocab,
y_vocab,
device,
bs_token_id=0,
eod_token_id=1,
max_padding=64,
pad_id=2,
):
"""Processes and collates a batch of text samples into padded tensors.
This function is designed to be used as a `collate_fn` for a PyTorch
DataLoader. It takes a batch of raw (input, target) string pairs,
applies processing pipelines (e.g., tokenization), converts tokens
to numerical IDs using vocabularies, adds special tokens (beginning-
of-sequence and end-of-sequence), and pads each sequence to a fixed
length.
Args:
batch (List[Tuple[str, str]]): A list of tuples, where each tuple
contains a raw input string and a raw target string.
x_pipeline: Input (x) tokenizer, spaCy-like.
y_pipeline: Target (y) tokenizer, spaCy-like.
x_vocab (Vocabulary): An instance of the Vocabulary
class, initiated with input vocabulary.
y_vocab (Vocabulary): n instance of the Vocabulary
class, initiated with target vocabulary.
device : The device (e.g., 'cpu', 'cuda').
bs_token_id (int, optional): The token ID for the beginning of a
sequence. Defaults to 0.
eod_token_id (int, optional): The token ID for the end of a
document or sequence. Defaults to 1.
max_padding (int, optional): The maximum length for each sequence.
Sequences will be padded to this length. Defaults to 64.
pad_id (int, optional): The token ID used for padding.
Defaults to 2.
Returns:
(torch.Tensor): The batched and padded input sequences.
(torch.Tensor): The batched and padded target sequences.
"""
bs_id = torch.tensor([bs_token_id], device=device)
eos_id = torch.tensor([eod_token_id], device=device)
x_list, y_list = [], []
for (x, y) in batch:
# Tokenize the input sequence and add BS and EoS tokens.
processed_x = torch.cat(
[
bs_id,
torch.tensor(
x_vocab(x_pipeline(x)),
dtype=torch.int64,
device=device,
),
eos_id,
],
0,
)
# Tokenize the target sequence and add BS and EoS tokens.
processed_y = torch.cat(
[
bs_id,
torch.tensor(
y_vocab(y_pipeline(y)),
dtype=torch.int64,
device=device,
),
eos_id,
],
0,
)
# Append the input & target sequences to respective lists.
x_list.append(
# WARNING: Overwrites values for negative values of
# (padding - len).
pad(
processed_x,
(0, max_padding - len(processed_x),),
value=pad_id,
)
)
y_list.append(
pad(
processed_y,
(0, max_padding - len(processed_y)),
value=pad_id,
)
)
x = torch.stack(x_list)
y = torch.stack(y_list)
return (x, y)def create_dataloaders(
device,
x_vocab,
y_vocab,
input_tok,
output_tok,
train,
validation,
batch_size=64,
max_padding=128,
):
"""Build training and validation PyTorch DataLoaders.
This function takes raw datasets, tokenizers, and vocabularies to
produce DataLoader instances that yield batches of processed,
tokenized, and padded tensors ready for model training and
evaluation.
Args:
device : The device (e.g., 'cpu' or 'cuda').
x_vocab (Vocabulary): An instance of the Vocabulary class,
initiated with input vocabulary.
y_vocab (Vocabulary): n instance of the Vocabulary class,
initiated with target vocabulary.
input_tok: Input tokenizer (spaCy-like).
output_tok: Output tokenizer (spaCy-like).
batch_size (int): The number of samples per batch.
Defaults to 64.
max_padding (int): The sequence length to which all samples
in a batch will be padded. Defaults to 128.
"""
def tokenize_input(text):
return tokenize(text, input_tok)
def tokenize_output(text):
return tokenize(text, output_tok)
def collate_fn(batch):
return collate_batch(
batch,
tokenize_input,
tokenize_output,
x_vocab,
y_vocab,
device,
bs_token_id=x_vocab.get_stoi()["<s>"],
eod_token_id=x_vocab.get_stoi()["</s>"],
max_padding=max_padding,
pad_id=x_vocab.get_stoi()["<blank>"],
)
# Build the train MapDataset & Data Loader
train_map = MapDataset([(ex["de"], ex["en"]) for ex in train])
train_dataloader = DataLoader(
train_map,
batch_size=batch_size,
shuffle=True,
collate_fn=collate_fn,
)
# Build the validation MapDataset & Data Loader
validation_map = MapDataset(
[(ex["de"], ex["en"]) for ex in validation]
)
valid_dataloader = DataLoader(
validation_map,
batch_size=batch_size,
shuffle=True,
collate_fn=collate_fn,
)
return train_dataloader, valid_dataloaderTraining Pipeline
Finally, it’s time to train our Transformer model!
Initialize the Transformer model
First, we build a function to create an object of the Transformer class and initialize it’s weights. We initialize the model weights using Xavier uniform distribution.
def make_model_translation(
k, heads,
x_seq_length,
y_seq_length,
x_vocab,
y_vocab,
n_encoders=2,
n_decoders=2
):
"""Build and Xavier-initialize a Transformer model.
Args:
k (int): Number of embedding dimentions.
heads (int): Number of heads.
x_seq_length (int): Maximum length of the input sequence.
y_seq_length (int): Maximum length of the output sequence.
x_vocab (int): Size of the input (source) vocabulary.
y_vocab (int): Size of the target vocabulary.
n_encoders (int): Number of Encoder blocks in the Transformer model.
n_decoders (int): Number of Decoder blocks in the Transformer model.
Returns:
(Transformer): A newly constructed and Xavier-initialized Transformer
model instance.
"""
model = Transformer(
k = k,
heads = heads,
x_seq_length = x_seq_length,
y_seq_length = y_seq_length,
x_vocab = x_vocab,
y_vocab = y_vocab,
n_encoders = n_encoders,
n_decoders = n_decoders,
)
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return modelTraining Loop
Now, let’s put together a function to train our Transformer model for an epoch.
def run_epoch(
data_iter,
model,
loss_compute,
optimizer=None,
scheduler=None,
epoch=0,
mode="train",
accum_iter=1,
train_state=TrainState(),
):
"""Runs a single training or evaluation epoch.
This function encapsulates the logic for a single pass over a dataset.
It handles iterating through batches, performing the model's forward
pass, computing the loss, and, if in training mode, executing the
backward pass with gradient accumulation and updating model weights.
Args:
data_iter (Iterable): An iterator that yields batch objects. Each
batch is expected to have attributes like `x`, `tgt`, `x_mask`,
`tgt_mask`, `tgt_y`, and `ntokens`.
model (torch.nn.Module): The PyTorch model to be trained or
evaluated. loss_compute (callable): An instance of the
SimpleLossCompute class.
optimizer (torch.optim.Optimizer, optional): The optimizer for
updating model weights. Required if `mode` is 'train' or
'train+log'. Defaults to None.
scheduler (torch.optim.lr_scheduler._LRScheduler, optional):
The learning rate scheduler. Required if `mode` is 'train' or
'train+log'. Defaults to None.
epoch (int, optional): The current epoch number, used for logging.
Defaults to 0.
mode (str, optional): The operational mode. Can be "train" or
"train+log" for training, or any other string (e.g., "eval") for
evaluation, which skips the backward pass and optimizer steps.
Defaults to "train".
accum_iter (int, optional): The number of batches to accumulate
gradients over before performing an optimizer step. Defaults to 1.
train_state (TrainState, optional): An instance of TrainState().
Returns:
(float): The average loss per token over the entire epoch.
(TrainState): The updated `train_state` object.
"""
start = time.time()
total_tokens = 0
total_loss = 0
tokens = 0
n_accum = 0
for i, batch in enumerate(data_iter):
# Forward pass through the transformer model.
out = model.forward(
batch.x, batch.tgt, batch.x_mask, batch.tgt_mask
)
# Loss calculation
loss, loss_node = loss_compute(out, batch.tgt_y, batch.ntokens)
if mode == "train" or mode == "train+log":
# Backward step
loss_node.backward()
train_state.step += 1
train_state.samples += batch.x.shape[0]
train_state.tokens += batch.ntokens
if i % accum_iter == 0:
# Optimizer step
optimizer.step()
optimizer.zero_grad(set_to_none=True)
n_accum += 1
train_state.accum_step += 1
# Learning rate scheduler step.
scheduler.step()
total_loss += loss
total_tokens += batch.ntokens
tokens += batch.ntokens
if (i % 10 == 0 and i > 0) and (mode == "train" or mode == "train+log"):
lr = optimizer.param_groups[0]["lr"]
elapsed = time.time() - start
print(
(
"Epoch: %6d | Step: %6d | Accumulation Step: %3d | Loss: %6.5f "
+ "| Tokens / Sec: %7.1f | Learning Rate: %6.1e"
)
% (epoch, i, n_accum, loss / batch.ntokens, tokens / elapsed, lr)
)
start = time.time()
tokens = 0
del loss
del loss_node
return total_loss / total_tokens, train_stateSubsequently, we will build the main training function.
def train_fn(
gpu,
k,
x_vocab,
y_vocab,
input_tok,
output_tok,
train,
validation,
config,
dir_path
):
"""Train a Transformer-based sequence-to-sequence translation model on
a single GPU and checkpoint weights after each epoch.
The function sets the active CUDA device, constructs the model and
loss, builds train/validation dataloaders, and runs a train→eval loop
for the requested number of epochs. Model weights are saved each
epoch using the prefix provided in config["file_prefix"] and once
more at the end as x<prefix>final.pt.
gpu (int): CUDA device index to use for this training process
(e.g., 0, 1, ...).
k (int): model embedding size.
x_vocab (Vocabulary): An instance of the Vocabulary class,
initiated with input vocabulary.
y_vocab (Vocabulary): n instance of the Vocabulary class,
initiated with target vocabulary.
input_tok: Input tokenizer (spaCy-like).
output_tok: Output tokenizer (spaCy-like).
train (List[(str, str)]): train dataset.
validation (List[(str, str)]): validation dataset.
dir_path (str): model save directory.
config (dict): Training configuration. Expected keys:
- "batch_size" (int): batch size per step.
- "max_padding" (int): Maximum sequence length (x/y) after padding.
- "base_lr" (float): Base learning rate for Adam.
- "warmup" (int): Number of warmup steps for the LR schedule.
- "num_epochs" (int): Number of training epochs.
- "accum_iter" (int): Gradient accumulation steps before an
optimizer step.
- "file_prefix" (str): Prefix for checkpoint file paths,
e.g. "model_".
"""
print(f"Train process using GPU: {gpu} for training", flush=True)
torch.cuda.set_device(gpu)
pad_idx = y_vocab.get_stoi()["<blank>"]
print("Max Padding: ", config["max_padding"])
# Initialize the Transformer model.
model = make_model_translation(
k=k,
heads=8,
x_seq_length=config["max_padding"],
y_seq_length=config["max_padding"],
x_vocab=len(x_vocab),
y_vocab=len(y_vocab),
n_encoders=config["n_encoders"],
n_decoders=config["n_decoders"]
)
model.cuda(gpu)
module = model
is_main_process = True
# Initialize label smoothing and loss function (KL Div)
criterion = LabelSmoothing(
size=len(y_vocab), padding_idx=pad_idx, smoothing=0.1
)
criterion.cuda(gpu)
# Build the train & validation data loaders
train_dataloader, valid_dataloader = create_dataloaders(
gpu,
x_vocab,
y_vocab,
input_tok,
output_tok,
train,
validation,
batch_size=config["batch_size"],
max_padding=config["max_padding"],
)
# Define the optimizer.
optimizer = torch.optim.Adam(
model.parameters(), lr=config["base_lr"], betas=(0.9, 0.98), eps=1e-9
)
# Define the learning rate scheduler.
lr_scheduler = LambdaLR(
optimizer=optimizer,
lr_lambda=lambda step: rate(
step, k, factor=1, warmup=config["warmup"]
),
)
# Define an instance of TrainState.
# To track key data points while training.
train_state = TrainState()
# Epoch loop!
for epoch in range(config["num_epochs"]):
# Model training.
model.train()
print(f"[GPU{gpu}] Epoch {epoch} Training ====", flush=True)
_, train_state = run_epoch(
(Batch(b[0], b[1], pad_idx) for b in train_dataloader),
model,
SimpleLossCompute(criterion),
optimizer,
lr_scheduler,
epoch,
mode="train+log",
accum_iter=config["accum_iter"],
train_state=train_state,
)
b = next(iter(valid_dataloader))
rb = Batch(b[0], b[1], pad_idx)
# Checking GPU utilization.
GPUtil.showUtilization()
if is_main_process:
os.makedirs(dir_path, exist_ok=True)
file_path = os.path.join(
dir_path, f"{config['file_prefix']}{epoch:02d}.pt"
)
torch.save(module.state_dict(), file_path)
torch.cuda.empty_cache()
print(f"[GPU{gpu}] Epoch {epoch} Validation ====", flush=True)
# Model evaluation.
model.eval()
sloss = run_epoch(
(Batch(b[0], b[1], pad_idx) for b in valid_dataloader),
model,
SimpleLossCompute(criterion),
optimizer=None,
scheduler=None,
epoch=epoch,
mode="eval",
)
print(sloss)
torch.cuda.empty_cache()
if is_main_process:
file_path = "%sfinal.pt" % config["file_prefix"]
torch.save(module.state_dict(), file_path)One final function to orchestrate model training,
def load_trained_model():
"""Initializes, trains, and then loads the Transformer model.
This function orchestrates the entire process of training and loading
a Transformer model. It calls the `train_fn` to execute the
training run.
Note:
This function relies on several globally defined variables:
`x_max_seq_len`, `y_max_seq_len`, `x_vocab`, `y_vocab`, `spacy_de`,
`spacy_en`, `train`, and `validation`.
Returns:
(torch.nn.Module): The trained Transformer model with its weights loaded.
"""
config = {
"k":512,
"batch_size": 32,
"num_epochs": 50,
"accum_iter": 1,
"base_lr": 0.1,
"max_padding": max(x_max_seq_len, y_max_seq_len) + 8,
"warmup": 3000,
"file_prefix": "wmt_2014_subset_model_",
"gpu":0,
"model_save_dir":"/content/drive/MyDrive/linkedin_posts/attention_is_all_you_need/models/run_2/",
"n_encoders":6,
"n_decoders":6
}
train_fn(
gpu=config["gpu"],
k=config["k"],
x_vocab=x_vocab,
y_vocab=y_vocab,
input_tok=spacy_de,
output_tok=spacy_en,
train=train,
validation=validation,
config=config,
dir_path=config["model_save_dir"]
)
model = make_model_translation(
k=config["k"],
heads=8,
x_seq_length=config["max_padding"],
y_seq_length=config["max_padding"],
x_vocab=len(x_vocab),
y_vocab=len(y_vocab),
n_encoders=config["n_encoders"],
n_decoders=config["n_decoders"]
)
model.load_state_dict(torch.load("wmt_2014_subset_model_final.pt"))
return modelInference Pipeline
A simple function to perform inference in a greedy decode fashion.
def greedy_decode(model, x, max_len, start_symbol):
"""Generates an output sequence using a greedy decoding approach.
This function encodes the input sequence and then
iteratively generates the output sequence one token at a time
by choosing the most likely next token at each step.
Args:
model: An instance of the Transformer class.
x (Tensor): The input sequence tensor of shape `(1, seq_len)`.
max_len (int): The maximum length of the generated output sequence.
start_symbol (int): The integer index for the
start-of-sequence token.
Returns:
(Tensor): The generated output sequence tensor of
shape `(1, max_len)`.
"""
device = "cpu"
model.eval()
encoder_out = model.encode(x, None)
y = torch.zeros(1, 1).fill_(start_symbol).type_as(x.data)
for i in range(max_len - 1):
prob = model.decode(
encoder_out, y, None, torch.triu(torch.ones((1, y.size(1), y.size(1))), diagonal=1)==1
)
_, next_word = torch.max(prob, dim=2)
next_word = next_word.data[0][-1]
y = torch.cat(
[y, torch.zeros(1, 1).type_as(x.data).fill_(next_word)], dim=1
)
return yAnalyzing Loss Trends
Next, let’s take a look at the training & validation loss plots. I experimented with
Training dataset size and,
The dropout probability.
Additionally, in all of the experiments below, the learning rate is varied in range that is an order of magnitude lower than the one recommended in Attention Is All You Need paper.
Furthermore, I did not train the Transformer model until validation loss plateaued since that would be too expensive. The one definitive inference we can draw from the experiments below is that our Transformer model does learn!
Note: I performed over 10 experiments. However, I am sharing loss plots on the 3 most interesting experiment runs. If you want to checkout plots from my other experiments as well, feel free to reach out to me on LinkedIn and I’ll be happy to share!
Experiment 1: dropout p = 0; training dataset size = 1M
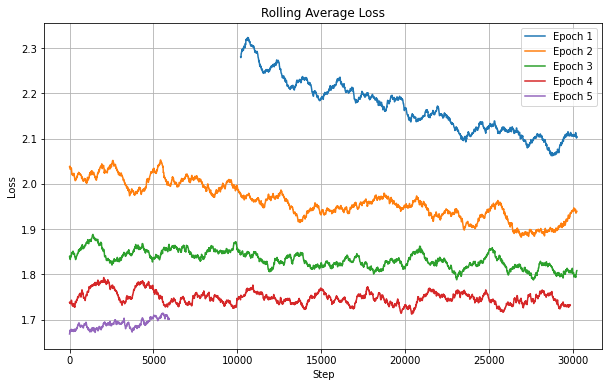
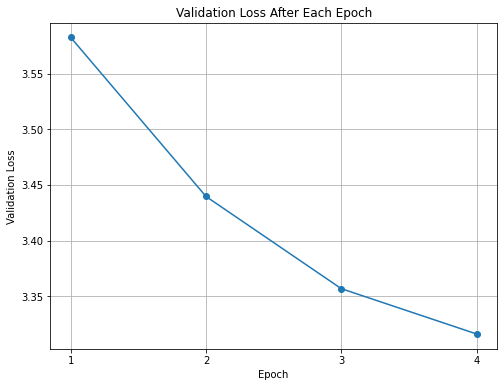
From Fig 2, we can observe that the validation loss is reducing and the curve’s trend seems to suggest that it might plateau in the next few epochs. The plateauing can be attributed to two reasons,
No dropout being implemented.
Less number of training examples.
Looking at Fig 1 and Fig 2, I believe the plateauing validation loss is due to a combined effect of both, missing dropout and small-ish training dataset.
Experiment 2: dropout p = 0.3; training dataset size = 1M
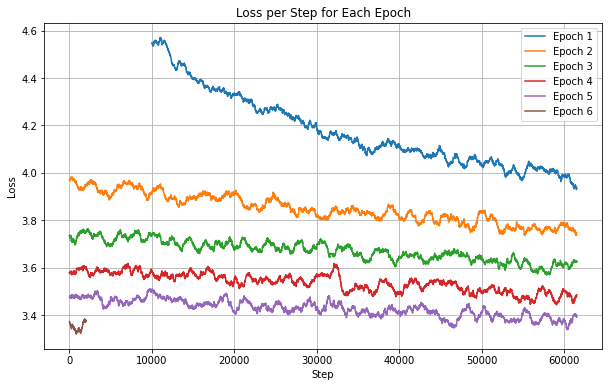
From Fig 4, we can observe that the validation loss curve has a similar slope at each epoch which tells us that the curve is not going to plateau anytime soon.
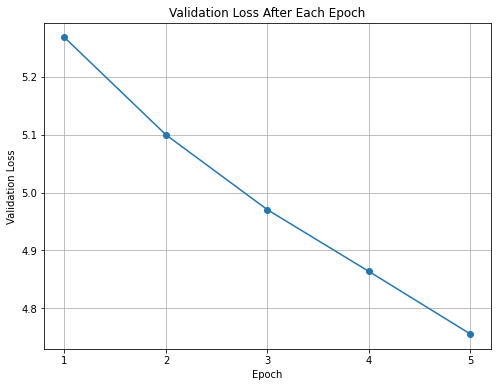
Experiment 3: dropout p = 0.3; training dataset size = 200k
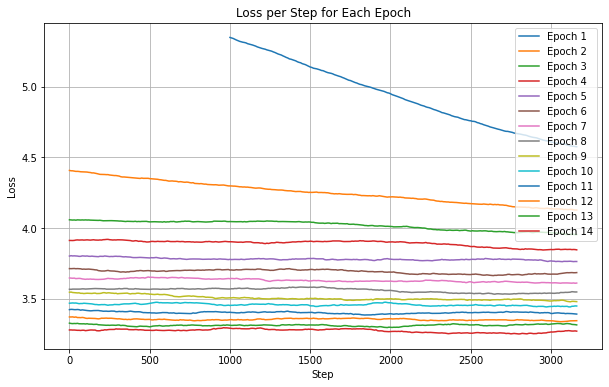
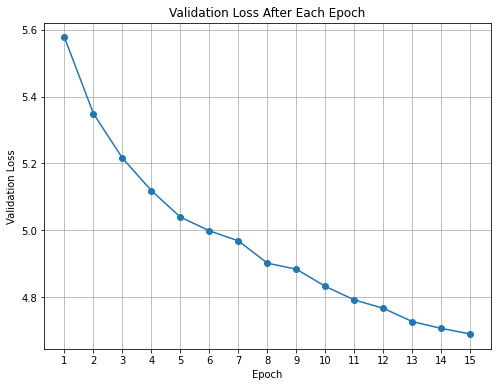
From Fig 6 we can observe that the gain in model performance (in terms of validation loss) has reduced quite a bit over the epochs 13 to 15 as compared to earlier epochs. I believe the validation loss might start plateauing in the next few epochs.
What Did I Learn?
My biggest takeaway from this project is a deep, practical understanding of the attention mechanism. I can now implement the mechanism in a Deep Learning model! This know-how is going to be a game-changer in my future projects.
From a modeling perspective, I now understand that dropout is extremely important for preventing a Transformer model from overfitting. In Experiment 1, I completely forgot to implement dropout and, we can observe the result of that!
Furthermore, Transformer models are extremely sensitive to small changes in the learning rate. In some of my experiment runs the model completely fails to learn due to the learning rate being a little bit high!
Finally, my most important takeaway - training a Transformer model is costly but, it is REWARDING!
Next Steps
I want to build a small foundational model from scratch. However, I need to do a lot more reading on how I can build such a model. Some of the papers I think will help are,
If you have recommendations on papers to read, please send me a message on LinkedIn!